This topic explains how to create an integration task to import occurrences of vulnerabilities from an XML file generated by a scanner that, by default, is not supported by the system.
The system already provides specific integration tasks for NeXpose and Qualys scanners. This task, on the other hand, allows vulnerabilities to be imported from any scanner that can export its scan reports to XML format. These occurrences are automatically included in the catalogue of vulnerabilities and mapped to their corresponding assets through the mapping criteria defined for each asset. For details on managing the catalogue of vulnerabilities, see Chapter 8: Knowledge -> Risk Knowledge -> Catalogue of Vulnerabilities.
The XML files generated by each scanner have specific structures for their headers, sections, content ID tags, and other elements. For the system to be able to import the information from these fields correctly, it must be able to understand the way in which each XML file is structured. Scanners from different manufacturers use their own terms and names to refer to the different properties of vulnerability occurrences. Thus, there is no guarantee that the XML reports generated by different scanners will use the same terminology to define the same property of a vulnerability – such as its name or level of severity, for example. Consequently, for the information to be imported correctly, the custom terms that appear in these reports must be mapped to the corresponding fields in the system.
For example, a certain scanner (S1) could use the term "Name" in its XML report to identify the names of the vulnerabilities it detected, whereas another scanner (S2) could use the word "Vulnerability". Similarly, S1 could use "Scoring" to define the risk metrics associated with each vulnerability, which S2 could refer to as "CVSS", and a third scanner (S3) could call "Risk Level", and so on.
It may also be that certain scanners include a certain type of information in their XML reports, whereas others do not. For example, S1 could provide information on the category of the vulnerabilities detected, while S2 does not. This might cause a problem when the reports are imported to the system. If a field is optional in the system, there will be no error in the system if it is left blank in the XML report that is imported; however, if a field that is required in the system (for example, the category of the vulnerability) is not included in the XML file, an error will occur when the integration task is run. To avoid this problem, a default value must be defined to be entered in each required field that is left blank or omitted in imported XML reports. Note that if two or more vulnerability scanners scan the same objects, the information will not be consolidated and there will likely be duplicate vulnerabilities reports for the scanned objects.
Another feature that can be used in this mapping is the conversion of numbers, as it may be that each scanner uses its own scale to specify the severity or risk levels of the vulnerabilities detected. For example, in scanner S1, the level of severity for each vulnerability may be calculated on a scale from 1 to 10, while scanner S2 may represent this same value on a scale from 1 to 5. In this case, if the expected values for severity scores range from 1 to 5 in the system, the values from the corresponding field in scanner S2 do not need to be converted when imported, as the system uses the same scale. For scanner S1, however, rules must be created to convert these values. In this case, values 1 and 2 can be converted to 1, values 3 and 4 can be converted to 2, and so on.
Below are presented all the fields that must be mapped to register each vulnerability occurrence identified in the assets. To write these mappings, you must inform the node in which the details of each occurrence are located in an asset. This configuration is made through the basePath by writing the absolute Xpath for the respective path in the vulnerability report. From this point on, the fields must be mapped through the Xpath related to the basePath.
|
Field |
Variable |
Description |
Required? |
Limit/Format |
|
IP Address |
ip |
Must contain the asset's IP address. |
Yes |
100 characters |
|
NetBIOS Name |
netbios |
Must contain the asset's NetBIOS name. |
No |
100 characters |
|
DNS Name |
fqdn |
Must contain the asset's FQDN. |
No |
100 characters |
|
Vulnerability ID |
id |
Must contain the vulnerability's ID. |
Yes |
100 characters |
|
Vulnerability |
name |
Must contain the vulnerability's name. |
Yes |
N characters |
|
Category |
category |
Must contain a name by which a group of vulnerabilities can be categorized. |
Yes |
100 characters |
|
Type |
type |
Must contain the type of the vulnerability. Must be mapped for the following values: confirmed, potential, or info. |
Yes |
N/A |
|
Level |
level |
Must contain a score between 1 and 5, which will be used to calculate risk. |
Yes |
1-5 |
|
Description |
description |
Must contain the description of the vulnerability. |
No |
N characters |
|
Impact |
impact |
Must contain details on the possible impact the exploitation of the vulnerability could have. |
No |
N characters |
|
Solution |
solution |
Must contain a solution for the vulnerability. |
No |
N characters |
|
Protocol |
protocol |
Must contain the protocol where the vulnerability occurs. |
No |
100 characters |
|
Port |
port |
Must contain the port where the vulnerability occurs. |
No |
Int |
|
Evidence |
evidence |
Must contain information demonstrating the occurrence of the vulnerability for the respective asset. |
No |
N characters |
|
CVSS Score |
cvss |
Must contain the CVSS of the vulnerability (value between 0 and 10). |
No |
0-10 |
|
BugTraqID |
bugtraq |
Must contain the BugTraq identifier of the vulnerability. |
No |
50 characters |
|
CVE-ID |
cve |
Must contain the CVE identifier of the vulnerability. |
No |
50 characters |
|
Other References |
reference |
Must contain references to where information on the vulnerability can be found. |
No |
1024 characters |
|
Last Update |
lastUpdated |
Must contain the update date for the vulnerability in a specific format. |
No |
datetime |
Note: For the Last Update field, the date must be entered in a specific format. To configure this format, see http://msdn.microsoft.com/en-us/library/8kb3ddd4.aspx.
<lastUpdated field="../scan_time" format="MMM dd HH:mm:ss yyyy" />
The following features are also available:
•Conversion/mapping of values to adhere to the system requirements. A clear example of this is the need to convert the Type and Level types:
<mappings> <add from="Critical Problem" to="confirmed" /> </mappings>
or
<mappings> <add from="10" to="5" /> </mappings>
•Converting content into a hash md5. In the example, this resource is used for the Vulnerability ID field, as the scanner providing the information does not provide a numeric identifier for the vulnerability.
<id field="description" hashed="true" />
•Defining default values for fields not included in the report.
<category field="category" default="Unknown" />
•Partition text to create a list of elements. The BugTraq ID, CVE-ID, and Other References are represented by a list in the system. A number of scanners treat this list as text with all these elements concatenated and separated by semicolons (;).
<cve field="cve" splitChar=";" />
•Limit the size of each type of text to respect the limits entered in the table above. If left undefined, an error will occur every time a file with content exceeding the allowed limit is imported.
<reference field="reference" truncate="true" />
The example below is the configuration for a report based on assets, where each asset is associated with a list with N vulnerabilities.
<?xml version="1.0" encoding="utf-16"?>
<config version="1" source="MySample">
<baseNode basePath="/report/details/host_info/vulnerability">
<occurrence>
<id field="description" hashed="true" />
<ip field="../ipaddr" />
<netbios field="../netbios" />
<fqdn field="../hostname" />
<name field="description" />
<category field="category" default="Unknown" />
<type field="severity">
<mappings>
<add from="Critical Problem" to="confirmed" />
<add from="Area of Concern" to="confirmed" />
<add from="Potential Problem" to="potential" />
<add from="Service" to="potential" />
<add from="Other Information" to="info" />
</mappings>
</type>
<level field="severity">
<mappings>
<add from="Critical Problem" to="5" />
<add from="Area of Concern" to="5" />
<add from="Potential Problem" to="3" />
<add from="Service" to="2" />
<add from="Other Information" to="1" />
</mappings>
</level>
<description field="description" />
<impact field="impact" />
<solution field="resolution" />
<protocol field="protocol" />
<port field="port" />
<evidence field="vuln_details" />
<cvss field="cvss" />
<bugtraq field="bugtraq" splitChar=" "/>
<cve field="cve" splitChar=" " />
<reference field="reference" truncate="true" />
<lastUpdated field="../scan_time" format="MMM dd HH:mm:ss yyyy" />
</occurrence>
</baseNode>
</config>
As the baseNode must contain the path for the node in the report that represents the occurrence, the path was configured to "/report/details/host_info/vulnerability". The information on the asset, on the other hand, must be searched for in the node above it (for example, …/ipaddr).
For the Category field, a default value ("Unknown") was specified so that no errors would occur when importing vulnerabilities without this property.
In this scanner, to obtain information on the type and level of the vulnerability, which are required, the content from the Severity field had to be mapped so that it could induce the values presented.
For the CVE-ID and BugTraq ID fields, the splitChar must be used for the importation to recognize that the content of the report is a text representing a list of these items, separated by a single space.
For the Other References field, the feature for truncating fields had to be used, since the scanner used presented more characters than the allowed limit.
The following report structures are accepted:
•Structure based on assets with the list of vulnerabilities:
<node of asset A>
<node of vulnerability 1/>
<node of vulnerability 2/>
...
<node of vulnerability N/>
</node of asset A>
<node of asset B>...</node of asset A>
...
<node of asset Z>...</node of asset Z>
•Structure based on vulnerability or occurrence, where each node of the vulnerability/occurrence contains information on the asset.
<occurrence A>...</occurrence A>
<occurrence B>...</occurrence B>
...
<occurrence Z>...</occurrence Z>
It is currently prohibited to configure relationships. If the node of a report does not contain all the necessary information and makes reference to another path in the report through an identifier, it will not be able to be mapped. Structure example:
<vulnerability 001/>
<vulnerability 002/>
<vulnerability N/>
<asset A/>
<asset B/>
<asset Z/>
<occurrence 001 x A/>
<occurrence 001 x B/>
<occurrence N x Z/>
XML files can be imported directly from your local computer or from a remote repository, such as a folder on the server where Modulo Risk Manager is installed. If you are using a SaaS environment, the XML files must be imported locally from your computer.
To import XML reports located in a remote repository, the complete path to the repository must be provided. Several XML files could be located in the same directory, since a single scanner can generate reports frequently. However, even if a report that has already been processed by the system is in the same directory as new reports, it will only be imported once.
If the directory specified contains a number of unprocessed XML reports generated by a scanner, they will all be imported. For this reason, it helps to specify the order in which the different unprocessed reports will be imported. Ideally, the oldest reports should be imported first, so as to respect the chronological order in which the vulnerabilities were detected. When configuring the integration task to import files from a remote repository, you can choose whether the order the files are imported will be by date or by name.
You can also import XML files that are stored locally on your computer. In this case, the order the files are imported follows the alphabetical order of the file names. Keep in mind that tasks to import files stored locally are executed immediately after being saved, so you do not need to create a schedule for them.
Vulnerabilities associated with the same asset are only imported once, even if they appear in several XML reports generated by scanners. Although the Qualys scanner has unique identifiers for vulnerabilities, there are other scanners that do not, which could register multiple entries in the system for the same vulnerability related to the same asset. However, Modulo Risk Manager uses a unique identifier for each vulnerability related to the same asset that is repeated in reports. When a scanner provides the unique identifier, it will be used. When it is not provided, the user will be able to indicate which field in the XML report should be used to identify each vulnerability.
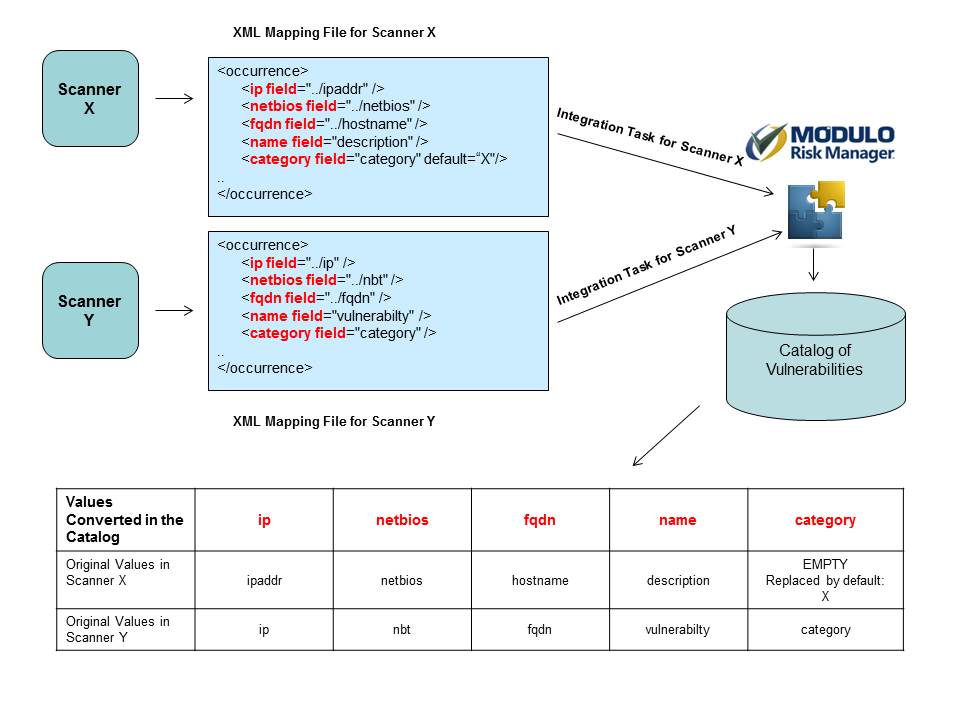
The figure below illustrates the concepts discussed so far. Note that the information referred to as "ipaddr" by scanner X is referred to as "ip" in scanner Y. In their respective XML reports, both will be recognized as compatible with the <ip> field in the catalogue, which is the name used by the system to identify the IP address of each asset analyzed. Similarly, what scanner X calls "description" and scanner Y calls "vulnerability" serves the same purpose as the <name> field, used by the system to represent the names of the vulnerabilities identified. Also note that "category" field in scanner Y is not available in scanner X, in which case a default value of "X" is entered in this field, so as to avoid errors when the report is imported. When imported, these values will be included in the Category field.
It is important to note that a separate integration task will have to be created for each scanner from which vulnerabilities will be imported. This allows specific mappings to be set for each scanner.
When creating an integration task of this type, you can select an option that allows notifications to be generated in the system when inconsistencies occur regarding the existence of vulnerabilities imported through the task and later sent to treatment. For instance, if a vulnerability is included in an XML report, imported and mapped to an asset through this integration task, and then sent to treatment through a risk project, the system will display notifications if the vulnerability is not found in subsequent imports of the same report. These notifications will appear in the risk project through which the vulnerability was sent to treatment, in the Home module for the user that was assigned as project leader, and in the Progress and Associations tabs of the event created to treat the vulnerability.
These notifications will also be generated when an asset in the scope of the risk project is removed from the XML file to be imported. This occurs because the vulnerabilities identified for that asset are no longer found, not necessarily because they do not exist but because the asset is no longer being analyzed by the scanner in that particular report. If the assets or vulnerabilities were purposely removed, the XML file should be renamed so as to prevent notifications from being generated erroneously. In addition, if different credentials or a different policy is used to access and scan the assets, this could prevent certain vulnerabilities from being again identified and generate erroneous notifications